A – 高维宇宙
裸的二分图匹配,匹配数除以二即可。
// A.cpp
#include <bits/stdc++.h>
using namespace std;
const int MAX_N = 100;
int head[MAX_N], n, current, matching[MAX_N], dfn[MAX_N], arr[MAX_N];
bool isPrime[2020];
struct edge
{
int to, nxt;
} edges[(MAX_N * (MAX_N - 1)) >> 1];
void addpath(int src, int dst)
{
edges[current].to = dst, edges[current].nxt = head[src];
head[src] = current++;
}
bool dfs(int u, int org)
{
for (int i = head[u]; i != -1; i = edges[i].nxt)
{
int to = edges[i].to;
if (dfn[to] != org)
{
dfn[to] = org;
if ((!matching[to]) || dfs(matching[to], org))
{
matching[to] = u;
return true;
}
}
}
return false;
}
int main()
{
freopen("prime.in", "r", stdin);
freopen("prime.out", "w", stdout);
memset(head, -1, sizeof(head)), memset(isPrime, true, sizeof(isPrime));
int ans = 0;
scanf("%d", &n);
for (int i = 1; i <= n; i++)
scanf("%d", &arr[i]);
for (int i = 2; i < 2020; i++)
if (isPrime[i])
for (int j = 2; i * j < 2020; j++)
isPrime[j * i] = false;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
if (isPrime[arr[i] + arr[j]])
addpath(i, j);
for (int i = 1; i <= n; i++)
if (dfs(i, i))
ans++;
printf("%d", ans / 2);
return 0;
}
B – 排队
这道题我在考场上 A 掉了,方法跟题解不太一样(欢迎来 Hack),当然复杂度可能会高一点。
我们考虑魔改 DFS 序,在进入节点之前先进行排序,排序之后 DFS 完了之后再进行标记。可以发现,这就是我们在不删除节点的情况下的最优放法:
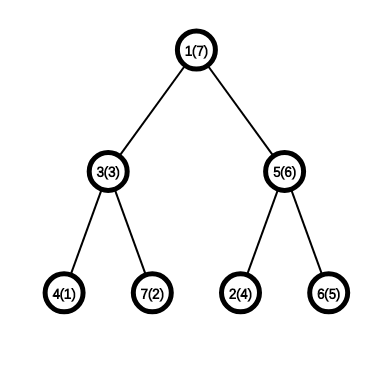
如上图所示,这就是我们在不搞删除的情况下放置的最佳顺序:4、7、3、2、6、5、1。我们定义这种顺序叫做乱搞序。我们来讨论使用一种乱搞的线段树(以上面那种顺序做关键字)来搞定这两个操作。
\(OPT = 1\)的情况下:我们先考虑之前没有删除操作的情况,其实很简单,直接往最后一个乱搞序最小的槽位设置为一即可;如果之前有过删除操作的话,那么已有的乱搞序上肯定不是连续的1:一定有个0表示被删除,我们可以考虑在 UPDATE 操作里面判断左右儿子是否有不满足连续的情况(也就是和等于区间长度),如果有那么就从加数里取出一些,如果加数有剩余,那么左儿子直接打标记,然后递归右儿子:因为我们设置 UPDATE 操作的返回值为最后一个乱搞值,之后通过 anti 数组重新转换为节点编号。
int update(int l, int r, int p, int c)
{
if (c == 0)
return -1;
if (l == r)
{
tree[p] += c;
return l;
}
int lft = (mid - l + 1) - tree[lson], rig = c - lft;
int ans = 0;
if (rig > 0)
{
tree[lson] = mid - l + 1, lazy[lson] = 1;
ans = update(mid + 1, r, rson, rig);
}
else
ans = update(l, mid, lson, c);
tree[p] = tree[lson] + tree[rson];
return ans;
}
\(OPT=2\)的情况下也比较简单,我们只要找出该节点到根节点链上的已用节点个数并减去一即可,进行单点修改。
建议详读代码,理解我的乱搞思想。
// B.cpp
#include <bits/stdc++.h>
#define mid ((l + r) >> 1)
#define lson (p << 1)
#define rson ((p << 1) | 1)
#define lowbit(x) (x & -x)
using namespace std;
const int MAX_N = 1e5 + 2000;
int n, t, dfn[MAX_N], st[20][MAX_N], tmpx, tmpy, tree[MAX_N << 2], lazy[MAX_N << 2], dtot, anti[MAX_N];
vector<int> G[MAX_N];
void addpath(int src, int dst) { G[src].push_back(dst); }
void pushdown(int p, int l, int r)
{
if (lazy[p] && l != r)
{
tree[lson] = mid - l + 1, tree[rson] = r - mid;
lazy[lson] = 1, lazy[rson] = 1;
}
lazy[p] = 0;
}
int update(int l, int r, int p, int c)
{
if (c == 0)
return -1;
if (l == r)
{
tree[p] += c;
return l;
}
int lft = (mid - l + 1) - tree[lson], rig = c - lft;
int ans = 0;
if (rig > 0)
{
tree[lson] = mid - l + 1, lazy[lson] = 1;
ans = update(mid + 1, r, rson, rig);
}
else
ans = update(l, mid, lson, c);
tree[p] = tree[lson] + tree[rson];
return ans;
}
void remove(int qx, int l, int r, int p)
{
if (l == r && l == qx)
{
tree[p] = 0, lazy[p] = 0;
return;
}
pushdown(p, l, r);
if (qx <= mid)
remove(qx, l, mid, lson);
else
remove(qx, mid + 1, r, rson);
tree[p] = tree[lson] + tree[rson];
}
bool query(int qx, int l, int r, int p)
{
if (l == r && l == qx)
return tree[p];
pushdown(p, l, r);
if (qx <= mid)
return query(qx, l, mid, lson);
else
return query(qx, mid + 1, r, rson);
}
void dfs(int u)
{
sort(G[u].begin(), G[u].end());
int siz = G[u].size();
for (int i = 0; i < siz; i++)
{
int to = G[u][i];
if (st[0][u] != to)
st[0][to] = u, dfs(to);
}
dfn[u] = ++dtot, anti[dfn[u]] = u;
}
int main()
{
scanf("%d%d", &n, &t);
for (int i = 1; i <= n - 1; i++)
scanf("%d%d", &tmpx, &tmpy), addpath(tmpx, tmpy), addpath(tmpy, tmpx);
dfs(1);
for (int i = 1; i < 20; i++)
for (int j = 1; j <= n; j++)
st[i][j] = st[i - 1][st[i - 1][j]];
while (t--)
{
int opt, x;
scanf("%d%d", &opt, &x);
if (opt == 1)
printf("%d\n", anti[update(1, n, 1, x)]);
else
{
int u = x, ans = 0;
for (int i = 19; i >= 0; i--)
if (st[i][u] != 0 && query(dfn[st[i][u]], 1, n, 1) == true)
u = st[i][u], ans += 1 << i;
printf("%d\n", ans);
remove(dfn[u], 1, n, 1);
}
}
return 0;
}
C – 心理学概论
我考场上以为是费用流,然后打凉掉了。
可以考虑先对序列进行排序(按第一、二和三关键字),然后再进行分段:二分出两个位置\(mid,mid1\),然后分成三段:\( [1,mid],[mid+1,mid1],[mid1+1,n] \)
之后统计即可。
// C.cpp
#include <bits/stdc++.h>
#define ll long long
using namespace std;
const int MAX_N = 1e5 + 1000;
struct cas
{
ll x, y, z;
bool operator<(const cas &cs) const { return x < cs.x || (cs.x == x && y < cs.y) || (y == cs.y && x == cs.x && z < cs.z); }
} cases[MAX_N];
ll n, ans1, ans2, ans3, ans;
int main()
{
freopen("psy.in", "r", stdin);
freopen("psy.out", "w", stdout);
scanf("%lld", &n);
for (int i = 1; i <= n; i++)
{
scanf("%lld%lld%lld", &cases[i].x, &cases[i].y, &cases[i].z);
ans1 = max(ans1, cases[i].x), ans2 = max(ans2, cases[i].y), ans3 = max(ans3, cases[i].z);
}
ans = min(ans1, min(ans2, ans3));
sort(cases + 1, cases + 1 + n);
ll l = 0, r = n, l1 = 0, r1 = n;
while (l < r)
{
ll mid = (l + r) >> 1;
l1 = 0, r1 = n;
bool flag = true;
while (l1 < r1)
{
ll mid1 = (l1 + r1) >> 1;
if (mid1 == mid)
if (mid1 + 1 <= r)
mid1++;
else if (mid1 - 1 >= l)
mid1--;
else
{
flag = false;
break;
}
ll k = 0;
for (int i = 1; i <= n; i++)
{
if (cases[i].x <= cases[mid].x)
continue;
if (cases[i].y <= cases[mid1].y)
continue;
if (cases[i].z > k)
k = cases[i].z;
}
ans1 = cases[mid].x + cases[mid1].y + k;
if (ans1 < ans)
ans = ans1, flag = true, r1 = mid1;
else
l1 = mid1 + 1;
}
if (flag)
r = mid;
else
l = mid + 1;
}
ll k = 0;
for (int i = 1; i <= n; i++)
{
if (cases[i].x <= cases[l].x)
continue;
if (cases[i].y <= cases[l1].y)
continue;
if (cases[i].z > k)
k = cases[i].z;
}
ans = min(ans, cases[l].x + cases[l1].y + k);
printf("%lld", ans);
return 0;
}